Chrome Extension Research Tools
Posted: Sept. 15, 2025
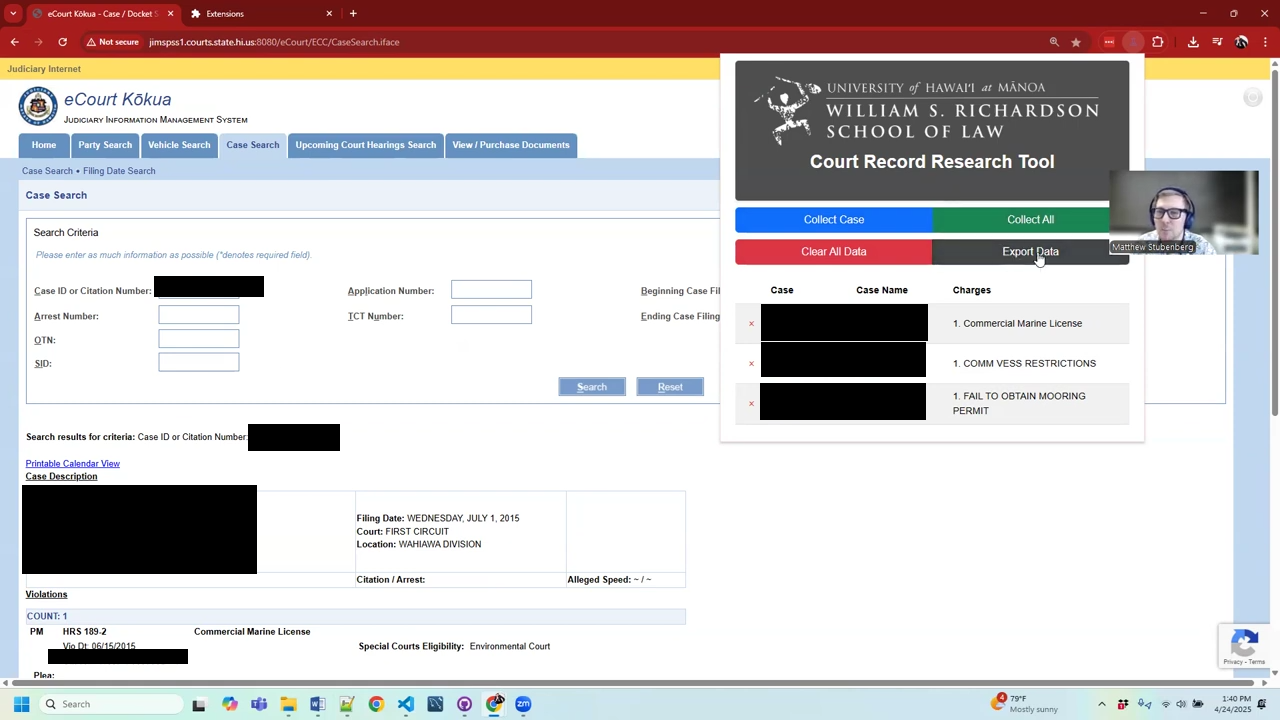
A common problem for researchers is getting the data out of Court websites to analyze. Sometimes this can be done with a information request or a web scraper. But sometimes because of strict rules, costs, and captchas, those options aren't available. Another option is to use a hybrid approach of part automation and part manual. In a recent instance where a colleague faced this issue we solved it by using a Chrome Extension. The problem was how to get the data for hundreds of cases. The purely manual way would be to search each case on the case search website and manually copy and paste each field you want into an excel sheet. However, this is terribly slow and extremely prone to data entry errors. The workaround we created was a chrome extension that when the user went to the case on case search, they could push the chrome extension button that was now added to their browser, and that extension would read all the content on the current page their looking at. It was programmed to pull out the relevant fields and add it to an internal excel sheet that could then be downloaded. Still a somewhat slow process because you had to manually go to each case and click the chrome extension button but this could now much more easily be farmed out to interns to handle.
Some additional features could include saving the HTML from that particular page in case you wanted to go back and get additional fields and create a record of what data you were looking at in case it gets changed in the future. I have been a big advocate for chrome extensions and their use in the legal field and they are criminally underused given their potential.
If you have a research project where you need to pull out lots of data from a website, send me an email and I'll see if the code I built previously might work for you.